Dieser Artikel ist der erste Teil einer Serie über die Sicherstellung der Performance von Unternehmensanwendungen in DevOps Szenarien. Wir gehen zunächst auf die grundlegenden Herausforderungen bei der Evaluation der Performance ein, der sich Software-Hersteller, -Betreiber oder -Nutzer durch DevOps Konzepte wie Continuous Delivery stellen müssen. In den folgenden Teilen dieser Artikelserie werden wir in Teil zwei die Perspektive der Entwicklung (Dev) beleuchten und vorstellen, welche Ansätze existieren, um die Herausforderungen aus Dev-Sicht zu adressieren. In Teil drei der Artikelserie nehmen wir die Perspektive des IT-Betriebs ein und beschreiben existierende Ansätze, um die Herausforderungen aus Ops-Sicht zu beleuchten.
Unternehmensanwendungen müssen kontinuierlich an die Marktsituation angepasst werden
Unternehmen müssen sich kontinuierlich an sich verändernde Marktsituationen anpassen. Diese Anpassungen müssen oft auch in den Unternehmensanwendungen (UA), welche die Geschäftsprozesse unterstützen, vollzogen werden. Hier einige Beispiele für typische Situationen in denen Anpassungen von UA notwendig sind [1]:
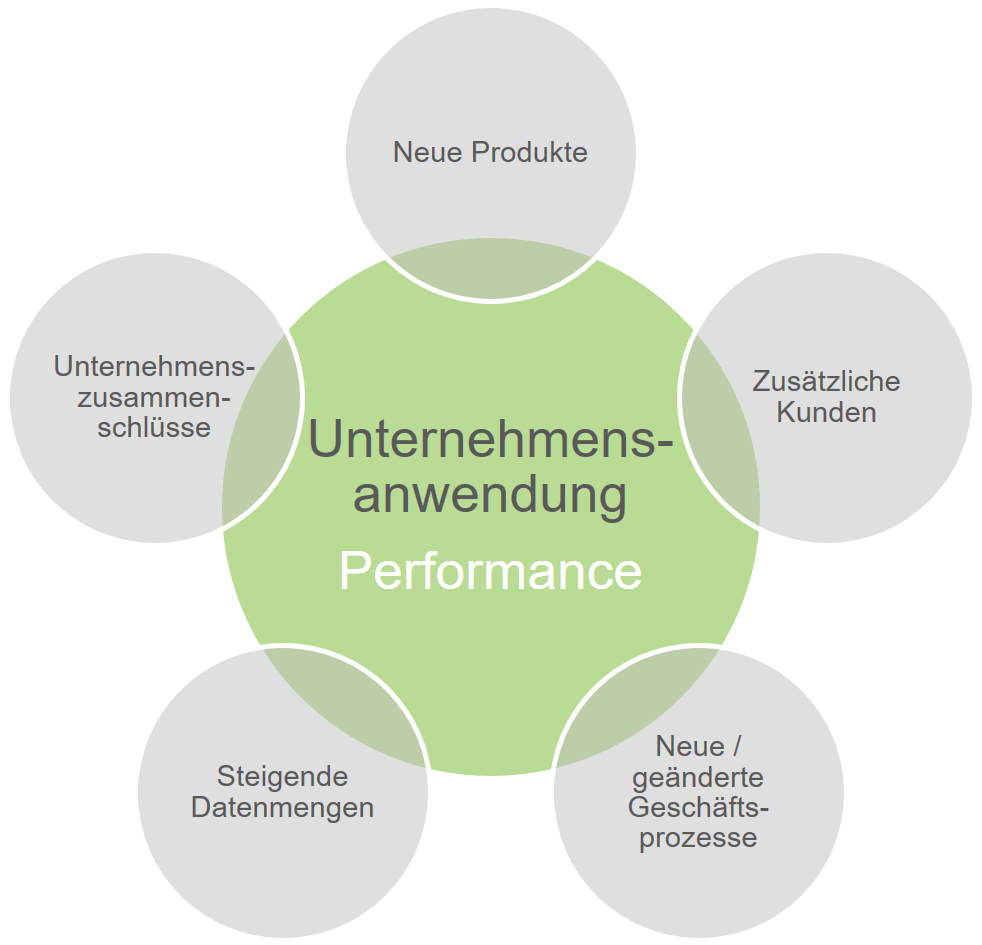
DevOps realisiert die dazu notwendige Flexibilität
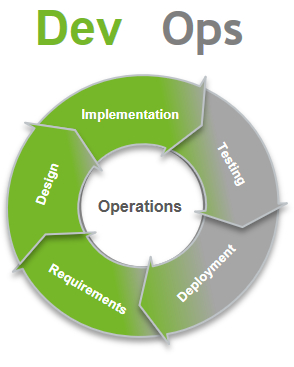
Um auch in der IT flexibel auf die sich ständig ändernden Anforderungen des Geschäftsumfeldes zu reagieren, hat sich in den letzten Jahren DevOps als aktueller Trend zur engeren Integration von Software-Entwicklung (Dev) und Betrieb (Ops) durchgesetzt [3]. Primäres Ziel von DevOps Konzepten ist es, die Releasefrequenz von Softwaresystemen zu erhöhen und damit die Zeit bis zur Verfügbarkeit neuer Features und Fehlerkorrekturen zu reduzieren [2,3]. Auf diese Weise können notwendige Veränderungen an den UA frühzeitiger in kleineren Releases ausgeliefert werden als dies in traditionellen Releasezyklen möglich gewesen wäre, da hier oft viele Features und Fehlerkorrekturen in großen Major-Releases gebündelt wurden. DevOps realisiert daher eine kontinuierliche Iteration von der Entwicklung in den Betrieb wie in der folgenden Abbildung dargestellt.
 Ein hoher Automatisierungsgrad ist die Voraussetzung für eine hohe Releasefrequenz
Ein hoher Automatisierungsgrad ist die Voraussetzung für eine hohe Releasefrequenz
Obwohl es keine allgemein anerkannte Definition gibt, was alles zu „DevOps“ gehört, scheint Einigkeit darüber zu herrschen, dass ein hoher Automatisierungsgrad aller Schritte von der Entwicklung bis in den Betrieb wesentlich für die Realisierung der schnelleren Releasefrequenzen ist [3]. Die Menge aller Schritte von der Entwicklung bis in den Betrieb kann durch eine Deployment Pipeline beschreiben werden (siehe folgende Abbildung, die aus [3] übernommen und angepasst wurde). Eine solche Pipeline kann durch Werkzeuge wie Ansible, Chef und Jenkins realisiert werden, die es alle ermöglichen, manuelle Aufgaben wie das Kompilieren, Paketieren und den Test von Software zu automatisieren.
 Nicht-funktionale Qualitätseigenschaften werden bisher nicht ausreichend in Deployment Pipelines evaluiert
Nicht-funktionale Qualitätseigenschaften werden bisher nicht ausreichend in Deployment Pipelines evaluiert
Während die Automatisierung dieser Schritte für die Realisierung und den Test von funktionalen Aspekten von Software bereits oft eingesetzt wird, ist die Automatisierung im Bereich der Evaluation der nicht-funktionalen Aspekte noch nicht in derselben Art und Weise ausgeprägt. In dieser Artikelserie beschäftigen wir uns mit dem Thema Performance im Sinne von Antwortzeit, Durchsatz und Ressourcenauslastung. Die Sicherstellung dieser Qualitätseigenschaft soll laut der Deployment Pipeline in der Abbildung oben in dem Schritt „Automated Capacity Testing“ durchgeführt werden. Humble und Farley [3] definieren bei diesen Kapazitätstests Kapazität als den höchsten Durchsatz, den ein System erreichen kann ohne definierte Antwortzeiten zu überschreiten. Dieser Zusammenhang ist in der folgenden Abbildung dargestellt.

Hohe Kosten für Performance-Testumgebungen
Die vorher genannte Definition von Kapazität erfordert eine Testumgebung, die vergleichbar ist mit der Produktionsumgebung. Ohne eine solche Umgebung sind Aussagen über die Kapazität nicht wirklich hilfreich, da sich Messergebnisse von kleineren Umgebungen nicht einfach linear hochrechnen lassen [6]. Solche Systeme stehen in den meisten Unternehmen meist nur begrenzt zur Verfügung, da die Kosten für die Anschaffung und Pflege einer enstsprechenden Umgebung meist sehr hoch sind. Darüber hinaus kommt es oft vor, dass eine UA auf unterschiedlichen Umgebungen betrieben wird, und die Anschaffung entsprechender Replikate für den Performance-Test meist nicht wirtschaftlich ist. Dies führt dazu, dass sich mehrere Teams die entsprechenden Performance Testsysteme teilen und immer nur begrenzt Testzeit zur Verfügung haben, wie in der folgenden Abbildung gezeigt.
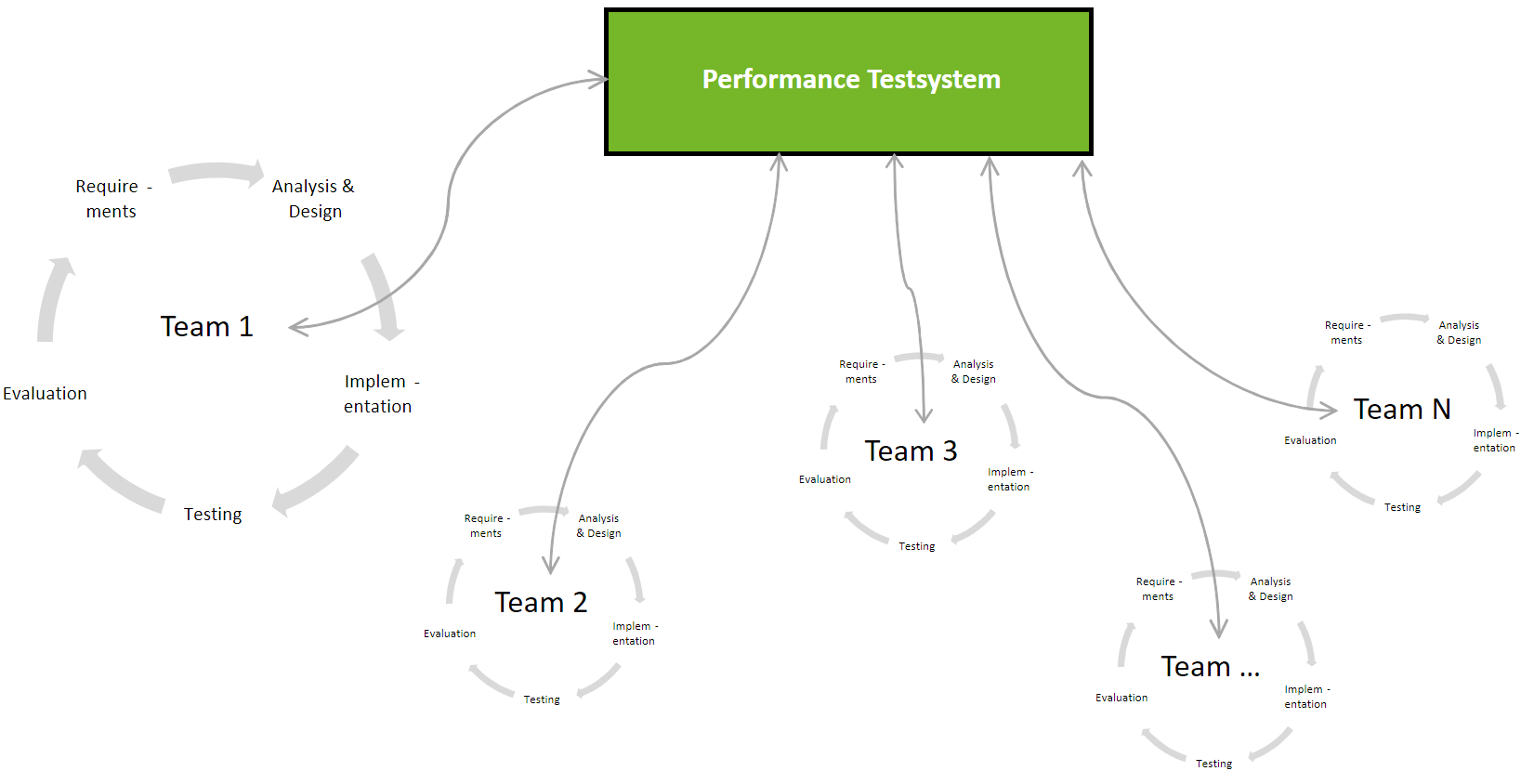 Geteilte Performance-Testumgebungen verhindern die Integration von Performance-Evaluationen in Deployment Pipelines
Geteilte Performance-Testumgebungen verhindern die Integration von Performance-Evaluationen in Deployment Pipelines
Da ein Performance-Test auf einer repräsentativen Umgebung mit einer entsprechenden Nutzerzahl meist eine hohe Vorbereitungszeit erfordert um die entsprechenden Testdaten und die Umgebungen zu erzeugen, führt die limitierte Verfügbarkeit von Testsystemen oft dazu, dass Performance-Tests nur auf einem kleinen Set an Testszenarien und -daten durchgeführt werden. Weiterhin sind durch diese Herausforderungen automatisierte Performance-Evaluationen nur schwer realisierbar. Daher stellt sich die Frage, wie man solche Performance-Evaluationen in einer Delivery Pipelines realisieren soll? Hierauf werden wir in Teil zwei dieser Serie eingehen, der bald auf retit.de erscheint!

Ohne Performance-Evaluationen sind Releases ein immenses Risiko für die Produktion
Durch die gerade erläuterte Problematik, dass jeder Build nicht automatisiert hinsichtlich Performance getestet werden kann, können die schnellen Releasefrequenzen dazu führen, dass eine Änderung, die zu einer deutlichen Performance-Regression führt, in Produktion geht. Im schlimmsten Fall führt das zu einer Überlastung und zum Ausfall der Systeme, da die aktuell verfügbare Rechenkapazität nicht ausreicht um den Produktionsworkload zu bewältigen. In den meisten Fällen werden solche Performance-Regressionen jedoch zu einer deutlichen Verschlechterung der Antwortzeiten führen. Manchmal sind jedoch neue Features geplant, die schnell in Produktion müssen, für die bewusst zusätzliche Rechenkapazität (On-Premise oder per Cloud) bereitgestellt werden muss. In Teil zwei dieser Serie werden wir darauf eingehen, wie man den Ops Teams entsprechende Informationen zur Verfügung stellen kann, um solche Performance-Probleme in der Produktion zu vermeiden.
Performance-Messdaten aus Produktion müssen Dev zur Verfügung stehen
Um den zu Beginn dieses Artikels aufgezeigten DevOps-Zyklus zu realisieren, ist nicht nur ein Informationsaustausch von Dev in Richtung Ops notwendig, sondern auch von Ops in Richtung Dev. Speziell zur Behebung von Performance-Problemen, die in Produktion auftreten, ist es erforderlich, den Entwicklern entsprechend detaillierte Informationen über die Performance einzelner Transaktionen zur Verfügung zu stellen. Diese Informationen können jedoch nicht nur zur Fehleranalyse genutzt werden, sondern auch um bessere Design-Entscheidungen oder die Auswahl von Testcases auf Basis des realen Nutzerverhaltens zu treffen. Teil drei dieser Serie geht darauf ein, wie dieser Informationsrückfluss realisiert werden kann.
[su_button url=“https://www.retit.de/software-performance-in-devops-teil-2-die-dev-perspektive/“ background=“#76B729″]Weiter zu Teil 2 der Serie[/su_button]
Haben Sie Fragen, Feedback oder Kommentare zu diesem Artikel oder stehen Sie vor ähnlichen Herausforderungen? Schreiben uns an info@retit.de, wir helfen Ihnen gerne!
Möchten Sie das Thema Software Performance bei Ihnen im Haus wieder auf die Tagesordnung bringen? Wir diskutieren es mit Ihnen und halten einen Impulsvortrag zum Thema Performance bei Ihnen vor Ort. Sie übernehmen nur die Reisekosten – Schreiben uns an info@retit.de!
[1] Grinshpan, L. (2012): Solving Enterprise Applications Performance Puzzles: Queuing Models to the Rescue. 1. edition. Wiley-IEEE Press, Piscataway, NJ, USA
[2] Humble, J.; Molesky, J. (2011): Why Enterprises Must Adopt Devops to Enable Continuous Delivery. Cutter IT Journal, vol. 24 no. 8, 6–12
[3] Humble, J.; Farley, D. (2010): Continuous Delivery: Reliable Software Releases Through Build, Test, and Deployment Automation. 1. edition. Addison-Wesley Professional, Upper Saddle River, NJ, USA
[4] Brunnert, Andreas; van Hoorn, André; Willnecker, Felix; Danciu, Alexandru; Hasselbring, Wilhelm; Heger, Christoph; Herbst, Nikolas; Jamshidi, Pooyan; Jung, Reiner; von Kistowski, Joakim; Koziolek, Anne; Kroß, Johannes; Spinner, Simon; Vögele, Christian; Walter, Jürgen; Wert, Alexander (2015): Performance-oriented DevOps: A Research Agenda, Technical Report SPEC-RG-2015-01, SPEC Research Group – DevOps Performance Working Group, Standard Performance Evaluation Corporation (SPEC).
[5] Brunnert, Andreas; Krcmar Helmut (2015): „Continuous Performance Evaluation and Capacity Planning Using Resource Profiles for Enterprise Applications“ Journal of Systems and Software, 2015, http://dx.doi.org/10.1016/j.jss.2015.08.030.
[6] Keith Smith, Bob Wescott (2007): Fundamentals of Performance Engineering: You Can’t Spell Firefighter Without It: Why We Fight Fires and How We Can Avoid Them in the First Place, HyPerformix Press.



