Dieser Artikel ist der zweite Teil einer Serie über die Sicherstellung der Performance von Unternehmensanwendungen in DevOps Szenarien. Im ersten Teil sind wir zunächst auf die grundlegenden Herausforderungen bei der Evaluation der Performance eingegangen, der sich Software-Hersteller, -Betreiber oder -Nutzer durch DevOps Konzepte wie Continuous Delivery stellen müssen. In diesem zweiten Teil werden wir die Perspektive der Entwicklung (Dev) beleuchten und vorstellen, welche Ansätze existieren, um die in diesem Teil vorgestellten Herausforderungen aus Dev-Sicht zu adressieren. In Teil drei der Artikelserie nehmen wir die Perspektive des IT-Betriebs ein und beschreiben existierende Ansätze um die Herausforderungen aus Ops-Sicht zu adressieren.
Klassische Performance-Evaluationsansätze sind wichtig aber nicht ausreichend
In der Softwareentwicklung wird Performance-Analyse in der Praxis meist erst dann durchgeführt, wenn eine lauffähige Version der Software verfügbar ist. Dies können frühe, prototypische, Versionen sein oder fast fertige Release Kandidaten. Um die Performance (im Sinne der Antwortzeit) dieser Softwarestände zu evaluieren werden häufig Methoden wie Einzelnutzertests in Kombination mit Profilingwerkzeugen sowie Lasttests mit vielen (virtuellen) Nutzern in Kombination mit eigenen Performance-Logs oder Monitoring Tools eingesetzt.
Einsatz von Profilingwerkzeugen
Bei dem Einsatz von Profilingwerkzeugen werden alle Bereiche einer Anwendung mit Messpunkten instrumentiert. Diese sehr tiefe Instrumentierung ermöglicht detaillierte Einblicke in das Verhalten und die Performance der Anwendung. Meist bekommt man mit Profilingwerkzeugen nicht nur Informationen über die Antwortzeiten einzelner Komponenten einer Anwendung, sondern auch über deren konkreten CPU- und Speicherbedarf. Diese Informationen sind sehr hilfreich um offensichtliche „Ressourcenfresser“ zu identifizieren und zu beseitigen. Einen Überblick über die grundlegenden Elemente beim Profiling finden Sie in der folgenden Abbildung (diese Abbildung wurde aus [3] übernommen):
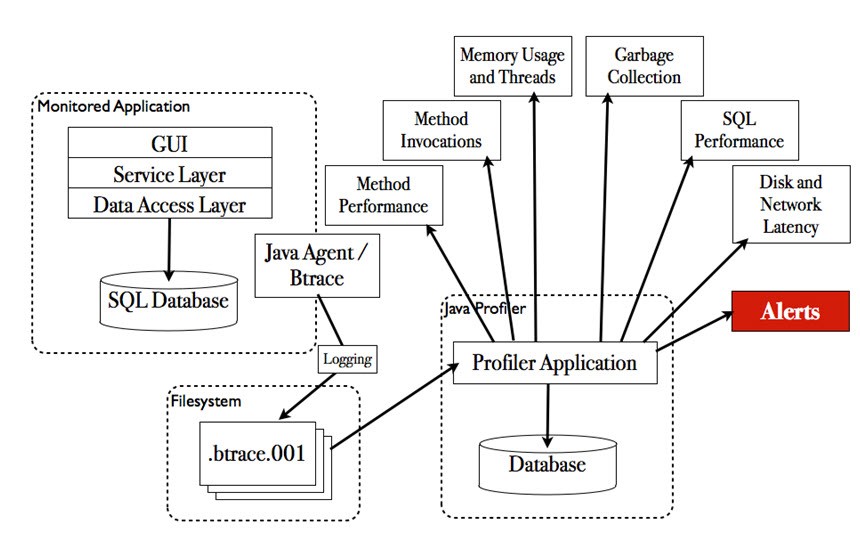
Eine große Problematik beim Einsatz dieser Werkzeuge ist jedoch, dass diese häufig auf Entwicklersystemen ausgeführt werden, die weder in Soft- und Hardware noch in der Anwendungskonfiguration vergleichbar mit dem Zielsystem sind. Beispiele für solche Unterschiede sind:
- Unterschiedliche CPU-Architekturen (z.B. Intel Xeon vs. AMD Opteron vs. IBM Power 8)
- Unterschiedliche Betriebssysteme (z.B. Linux vs. Windows vs. Unix vs. Solaris)
- Fehlende Anbindung von Backendsystemen (z.B. Einsatz von Service-Mocks)
Aus diesem Grund können die Ergebnisse von Profilings zum einen falsche Indizien geben, da sich das Verhalten durch Konfigurationsänderungen ändern kann, und zum anderen bestimmte Bottlenecks nicht sichtbar sind aufgrund der unterschiedlichen Datenmengen, die durch die implementierten Algorithmen verarbeitet werden. Darüber hinaus können Profilinganalysen keine Erkenntnisse darüber liefern, wie sich eine Anwendung im Mehrnutzerbetrieb verhält, da die hohe Menge an Instrumentierungspunkten die Anwendung so sehr verlangsamt, dass meist nicht mehr als ein Nutzer parallel mit dem System interagieren kann.
Einsatz von Lasttests mit Messwerkzeugen
Um die Nachteile von Profilingergebnissen auszugleichen werden meist in späteren Projektphasen Lasttests ausgeführt bei denen mehrere (virtuelle) Nutzer emuliert werden und die Anwendungsperformance während der Tests mit Messwerkzeugen vermessen wird. Was genau unter Lasttests verstanden wird unterscheidet sich meist je nach Unternehmen. Eine in unseren Augen sinnvolle Übersicht zur Unterscheidung unterschiedlicher Lasttest-Typen findet sich in [4] und wird in der folgenden Tabelle dargestellt:
| Lasttest-Typ | Beschreibung |
|---|---|
| Stresstest | Last soweit erhöhen bis System funktionale Fehler erzeugt, ausfällt oder Antwortzeiten eine bestimmte Grenze erreichen |
| Dauerlasttest | Kontinuierlicher Lasttest über bestimmten Zeitraum |
| Fail-Over-Test | Unter Last werden Ausfall und Wiederinbetriebnahme einzelner Systemkomponenten geprüft |
| Performance-Test | Test mit der maximal erwarteten Last auf Einhaltung der vorgegebenen Performance-Anforderungen und Auffinden von Bottlenecks |
| Sizing-Test | Grenzen unterschiedlicher HW/SW-Konfigurationen ermitteln, um später bei gegebenen Lastanforderungen die voraussichtlich benötigte HW und SW abschätzen können |
| Skalierbarkeitstest | Prüft… 1. … Antwortverhalten und Ressourcenverbrauch bei steigender Last 2. … verarbeitbare Last bei Hinzunahme von HW- und SW-Komponenten |
All diesen Lasttest-Typen ist gemeinsam, dass die Soft- und Hardware für die Tests vergleichbar mit der Produktionsumgebung sein muss. Sollten die Soft- und Hardwarekomponenten nicht vergleichbar sein, sind die so erhobenen Messdaten nicht repräsentativ. Dies ist ein spezielles Problem, da sich die Messwerkzeuge, die bei der Ausführung von Lasttests eingesetzt werden, meist auf die Performance-Metriken Antwortzeit, Durchsatz und Ressourcenauslastung fokussieren. Diese Metriken sind die Konsequenz einer bestimmten Last auf einer bestimmten Umgebungskonfiguration, sie beantworten also die Frage wie bestimmte Ressourcenbedarfe (CPU, Memory, HDD, Netzwerk) von der darunter liegenden Umgebung verarbeitet werden. Wird die Umgebungskonfiguration geändert (z.B. bei der Verschiebung einer Anwendungsversion von der Test- auf die Produktionsumgebung), können diese Ressourcenbedarfe bei derselben Last zu ganz anderen Antwortzeiten, Durchsatz und Auslastungsdaten führen.
Um dieses Problem zu adressieren, gibt es wissenschaftlich fundierte Methoden im Bereich der Performance-Modellierung und -Simulation! Diese werden in den RETIT Lösungen RETIT Capacity Manager (RCM) und RETIT Continuous Delivery (RCD) implementiert und ermöglichen es Ihnen auf Basis von Messdaten, die auf kleiner dimensionierten oder mit anderer Hardware ausgestatteten Testumgebungen erhoben wurden, die Performance-Metriken Antwortzeit, Durchsatz und Ressourcenauslastung auf unterschiedlichen Zielumgebungen zu simulieren – siehe folgende Abbildung. RCM und RCD ermöglichen es Ihnen daher, die in Teil 1 dieser Serie vorgestellten Herausforderungen des Mangels an repräsentativen Testsystemen zu umgehen, da Sie auf kleineren Umgebungen die notwendigen Daten sammeln können und durch Simulation die für Sie relevanten Metriken erheben können!
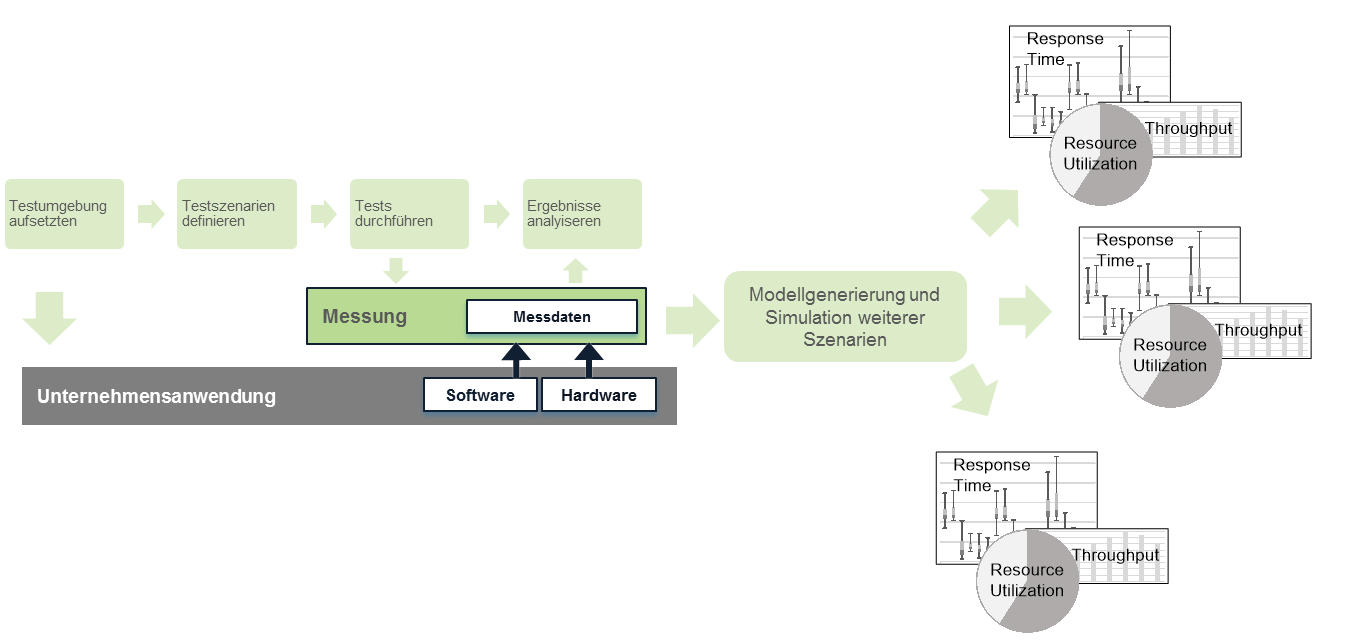
Zur Durchführung ist es erforderlich, dass während der Lasttests durch das eingesetzte Messwerkzeug die Ressourcenbedarfe bestimmter Softwarekomponenten erhoben werden. Diese Fähigkeiten realisieren moderne Application Performance Management (APM) Lösungen wie AppDynamics oder Dynatrace ohne den für das Profiling notwendigen Overhead, da deutlich weniger instrumentiert wird. Daher ist es in den meisten Szenarien unproblematisch, diese Messwerkzeuge während der Lasttests mitlaufen zu lassen. Falls Sie bisher keine APM-Lösung im Einsatz haben, bieten wir für Java Enterprise Edition (EE) Systeme die Lösung RETIT Java Enterprise Edition (RETIT JEE) zur Erhebung der notwendigen Daten an.
Insbesondere bei den schnellen Releasezyklen heutzutage stellt sich die Frage, ob es überhaupt noch tragbar ist, auf die Verfügbarkeit einer Performance-Testumgebung zu warten. Jede Wartezeit verzögert den Release und verhindert daher das Erreichen des eigentlichen Ziels der DevOps-Konzepte: Die Zeit bis zur Verfügbarkeit neuer Features und Fehlerkorrekturen zu reduzieren (siehe Teil 1 dieser Serie). RCD, RCM und RETIT JEE helfen Ihnen, dieses Ziel zu erreichen ohne massive Investitionen in neue Testumgebungen!
Frühzeitige Performance-Evaluation und Nutzung von existierenden Ops-Daten sparen Zeit und Geld
Die bisher vorgestellten Ansätze Profiling und Lasttest sind wie bereits erwähnt diejenigen, die in der Praxis am häufigsten zur Performance-Evaluierung angewendet werden. Sie benötigen jedoch eine lauffähige Anwendung und komplexe Testumgebungen. Daher sind bis zur Durchführung dieser Ansätze bereits viele Entwicklungsschritte (Design, Entwicklung, funktionaler Test) abgeschlossen und müssen wiederholt werden, sollten Performance-Probleme auftreten. Dies führt dazu, dass die relativen Kosten um Performance-Probleme zu beheben, die durch den Einsatz von Profilingwerkzeugen und Lasttests gefunden wurden, sehr hoch sind. Es ist daher wünschenswert, die Probleme möglichst früh im Prozess zu identifizieren um das mehrfache Durchlaufen der Entwicklungsschritte zu vermeiden:
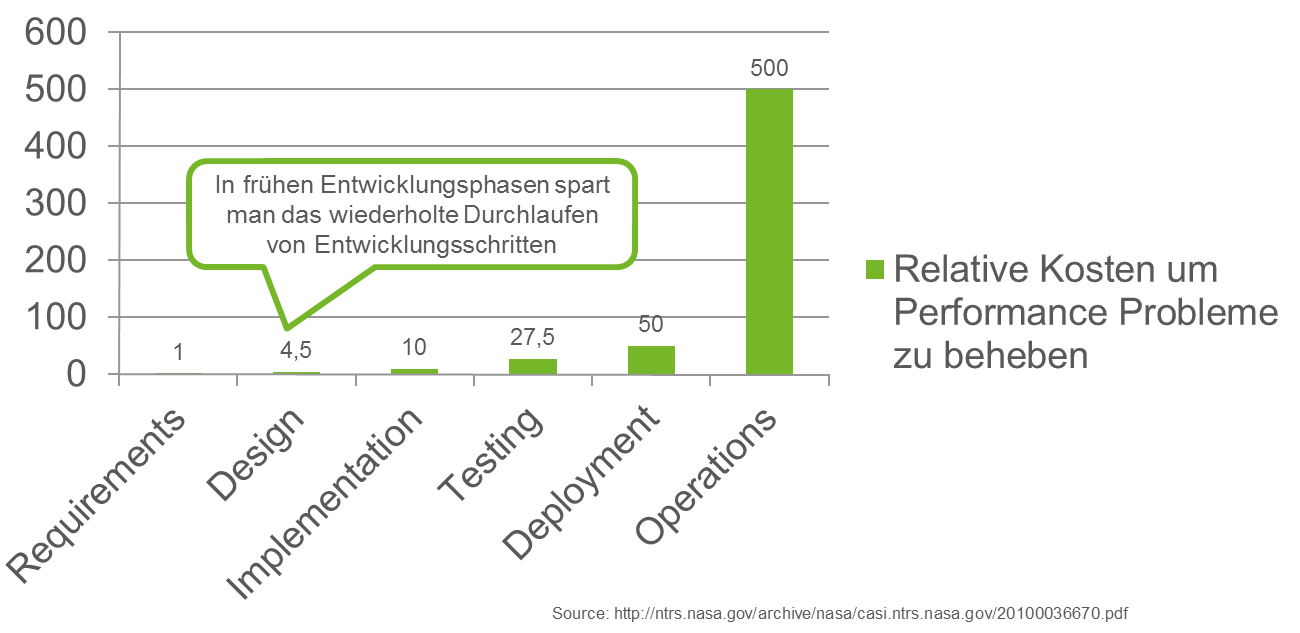
Wie jedoch kann man diese Kostenoptimierung erreichen? Die Lösung liegt in dem effizienten Einsatz existierenden Wissens! Nutzen Sie die Messdaten aus der Produktion um während der Design-Phase Performance-Simulationen mit RCM durchzuführen und frühzeitig Korrekturen an der Software-Architektur vorzunehmen. Weiterhin kann die Nutzung von Messdaten (insbesondere Webserver-Logs) aus dem Produktionssystem helfen zu identifizieren, ob die richtigen Testfälle getestet werden oder um überhaupt (Performance-)Testfälle abzuleiten [5]. So kann vermieden werden, dass man viel Aufwand in den Test von Testfällen steckt, die von den Anwendern kaum verwendet werden.
Die frühzeitige Performance-Simulation in der Design-Phase ist möglich, da selten Anwendungen auf der „grünen Wiese“ entwickelt werden. Die meisten Anwendungen nutzen Services, die von existierenden Systemen bereitgestellt werden. Allein durch die Nutzung der Antwortzeitdaten oder Service-Level-Agreements (SLAs) mit diesen Service-Anbietern und einer Architekturbeschreibung der neuen Anwendung über die Interaktion mit diesen Services, können mit RCM bereits in der Design-Phase Aussagen darüber getroffen werden, ob die Performance des Gesamtsystems den Erwartungen der Nutzer entspricht. Auf unserer Webseite finden Sie einen Artikel, der den Einsatz der RCM Lösung in einem Kundenprojekt zur frühzeitigen Performance-Evaluation beschreibt.
DevOps-Konzepte unterstützen die frühzeitige Performance-Evaluation, da durch die kontinuierliche Iteration zwischen Entwicklung und Betrieb viele Daten über die Anwendung vorliegen und diese nur den Entwicklungsteams zugänglich sein müssen um die vorher aufgezeigte Kosteneinsparung zu realisieren!
Performance-Metrik-basierte Deployment Pipelines
Wie bereits in Teil 1 dieser Serie beschrieben, ist Automatisierung eine wesentliche Voraussetzung zur Realisierung schnellerer Releasezyklen. Möchte man jedoch jetzt für jeden Build automatisiert kontrollieren, ob sich die Performance verbessert oder verschlechtert hat, müssen zunächst einmal Metriken definiert werden, die über die Güte der Performance entscheiden. Im Anschluss daran kann dann entschieden werden, durch welche Werkzeuge diese Metriken in welchem Schritt erhoben werden können.
In [1] werden neben den Standardmetriken Antwortzeit, Durchsatz und Ressourcenauslastung folgende Metriken empfohlen:
- Anzahl der Datenbankinteraktionen (z.B. wie viele SQL-Statements werden pro Nutzeraktion abgesetzt)
- Anzahl der Bilder auf einer Webseite und deren Größe
- Anzahl Exceptions
- Anzahl der verwendeten Datenbankverbindungen
- Größe von Threadpools und Anzahl der genutzten Threads
Die Erhebung dieser Metriken ist sinnvoll, da all diese Aspekte einen direkten Einfluss auf die gesamte Performance eines Softwaresystems haben. Viele diese Metriken (speziell 1-3) erfordern noch nicht einmal hohe Nutzermengen um sie zu erheben, da diese sich meist nicht wesentlich ändern, wenn die Last erhöht wird (unter der Annahme, dass es sich bei 3 um funktionale Exceptions handelt). Für die Evaluation von 4 und 5 sowie der Evaluation der Standardmetriken Antwortzeit, Durchsatz und Ressourcenauslastung sollten jedoch Tests mit entsprechend hohen Lasten durchgeführt werden, da diese sonst nicht repräsentativ sind.
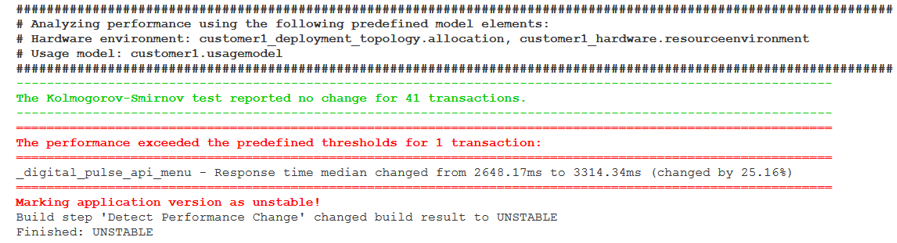
Wie geht man dies an? Nutzen Sie während Ihrer funktionalen Akzeptanz- und Regressionstests das Monitoringwerkzeug Ihrer Wahl um die Metriken zu erheben, die keine hohen Nutzerlasten benötigen (siehe 1-3). Weiterhin sollten diese Messungen auch die Ressourcenbedarfe (CPU, Memory, HDD; Network) einzelner Komponenten ermitteln. Dann können Sie im folgenden Schritt RCD einsetzen um die Performance jeder Anwendungsversion auch in hohen Lastszenarien zu evaluieren! RCD verbindet sich dann automatisch mit dem von Ihnen eingesetzten Messwerkzeug und realisiert die im folgenden Bild dargestellte „Performance Change Detection“, also die automatisierte Änderungserkennung der Performance Ihrer Anwendungen für unterschiedliche Workloads und Hardware-Umgebungen!
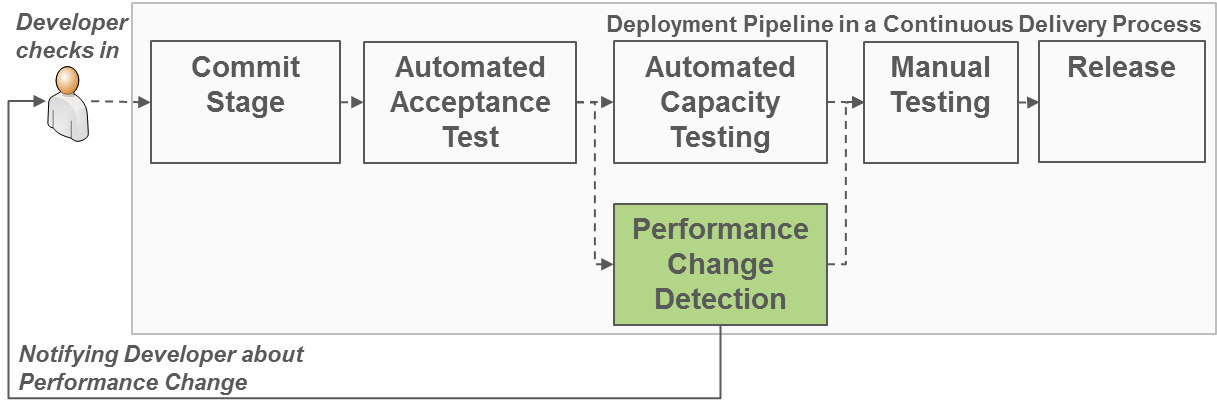
RCD ist fest integriert mit dem Continuous Integration Werkzeug Jenkins und bietet daher eine komfortable Konfiguration der für die automatisierte Performance-Evaluation notwendigen Parameter. Wir bieten die für RCD notwendigen Fähigkeiten zusätzlich als Kommandozeilenwerkzeug an, damit Sie es flexibel in ein Continuous Delivery Werkzeug Ihrer Wahl integrieren können!Das Ergebnis einer RCD Analyse eines Builds in Jenkins finden Sie in der folgenden Abbildung. Dies ist genau der Ausschnitt, den ein Entwickler bei Jenkins im Falle eines Build-Fails per EMail bekommen würde, er zeigt auf einen Blick die Probleme die gefunden wurden. Sie sehen in diesem Beispiel, dass sich die Antwortzeiten für 41 unterschiedliche Business-Transaktionen einer Kundenanwendung nicht geändert haben, sich die Antwortzeit einer Transaktion jedoch um 25 % (Median) erhöht hat. Wichtig ist es hierbei, dass diese Analyse für eine bestimmte Workload- (customer1.usagemodel) und Hardwarekonfiguration (customer1_deployment_topology.allocation, customer1_hardware.resourceenvironment) durchgeführt wurde, die unabhängig ist von der Umgebung auf der die Messdaten erhoben wurden!
Sie können einfach durch den Einsatz von RCM verschiedene Modelle der gewünschten Hardwareumgebung und des erforderlichen Workloads in RCD hochladen. Diese werden dann automatisiert zur Performance-Evaluation in Ihrer Deployment Pipeline genutzt! Diese Modelle müssen Sie auch nicht notwendigerweise selbst erstellen, sondern können sie aus Ihren produktiven Systemen ableiten – z.B. wie vorher schon angesprochen, um die korrekten Testfälle zu simulieren.
Auslieferung der Modelle an Ops zur Kapazitätsplanung
Die von RCD für jede Version erstellen Modelle können nach dem Release einer Anwendungsversion gemeinsam mit den Anwendungspaketen ausgeliefert werden. Stellen Sie sich dies ähnlich wie Systemanforderungen bei Desktop-Software, nur übersetzt auf komplexe betriebliche Informationssysteme vor. Auf diese Weise bekommt das Ops-Team neben den eigentlichen Anwendungspaketen auch eine Beschreibung der Ressourcenbedarfe dieser Anwendungspakete und kann durch Performance-Simulation mit Hilfe von RCM die für den Betrieb notwendige Kapazität berechnen. Dies hilft dabei Geld einzusparen, da die so oft getroffenen linearen Annahmen durch konkrete Simulationsergebnisse ersetzt werden, auf diese Weise wird das bisherige „Guess-Work“mit einer wissenschaftlich fundierten Basis ersetzt.
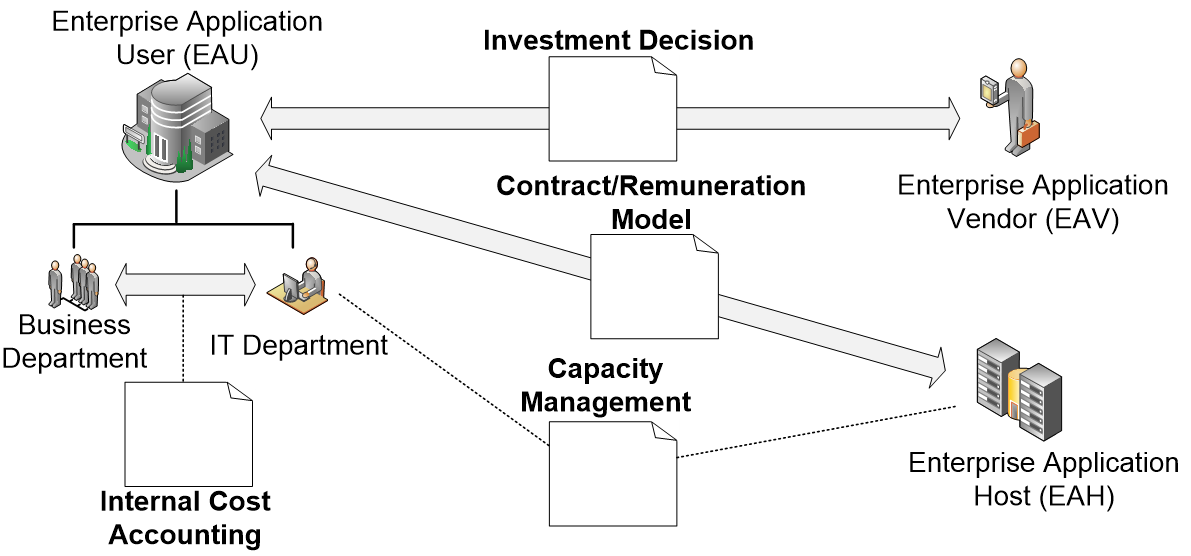
Dadurch, dass Sie automatisiert immer neue Performance-Modellversionen für jeden Software-Release bekommen, können Sie diese nicht nur zur Kommunikation mit einem Ops-Team, sondern in unterschiedlichen Anwendungsszenarien einsetzen. Ein paar Beispiele sind in der folgenden Abbildung dargestellt und nachfolgend beschrieben:
- Interne Kostenumlage (Internal Cost Accounting):
- Viele Systeme, seien es aktuell Cloud-Instanzen oder Rechenzeit auf einem Mainframe kosten den Nutzer umso mehr Geld je intensiver sie genutzt werden. Speziell bei Mainframes sind CPU-Zeit-basierte Abrechnungen immer noch üblich und auch in der Cloud zahlt man oft nicht mehr rein zeitbasiert, sondern auch entsprechend des Ressourcenverbrauchs, z.B. bei der Nutzung von Netzwerkressourcen. Durch die Nutzung der durch RETIT erstellten Modelle kann simuliert werden, wie viel Ressourcenauslastung durch bestimmte Abteilungen oder Nutzertypen und ihre Workloads erzeugt wird und auf Basis dieses Wissens die Kosten gerecht umgelegt werden.
- Vertragsgestaltung (Contract / Remuneration Model):
- Bei dem externen Betrieb von IT durch einen Rechenzentrumsdienstleister können die modellbasierten Simulationen zur Vertragsgestaltung genutzt werden. Es ist heutzutage, speziell bei Cloud-Anbietern, eine herausfordernde Aufgabe zu entscheiden, welche „Klasse“ (z.B. kleine, mittlere, große oder reservierte Instanzen) von Maschinen man mietet und wie viele davon. Wenn man durch Simulation verschiedene Kombinationen ausprobieren kann, spart man sich viel Geld und Zeit!
- Kapazitätsmanagement (Capacity Management)
- Sollten sich durch saisonale Änderungen oder wesentliche neue Funktionen geänderte Anforderungen an die Kapazität einer Anwendung ergeben, können die Modelle genutzt werden um die Änderungen entsprechend zu planen.
- Investitionsentscheidungen
- Sollten Sie als Softwarehersteller RCD und RCM einsetzen, können Sie Ihren Kunden einen klaren Mehrwert geben, da Sie durch den Einsatz von RCM konkrete Sizing-Recommendations geben können. Aus Sicht des Kunden ergibt sich der Vorteil, dass er nicht auf Basis eines rudimentären Sizing-Spreadsheets investieren muss und erst durch ein aufwändiges Kapazitätsplanungsverfahren zu einer Hardware-Recommendation kommt. Beide Seiten gewinnen!
[su_button url=“https://www.retit.de/software-performance-in-devops-teil-3-die-ops-perspektive/“ background=“#76B729″]Weiter zu Teil 3 der Serie[/su_button]
Haben Sie Fragen, Feedback oder Kommentare zu diesem Artikel oder stehen Sie vor ähnlichen Herausforderungen? Schreiben uns an info@retit.de, wir helfen Ihnen gerne!
Möchten Sie das Thema Software Performance bei Ihnen im Haus wieder auf die Tagesordnung bringen? Wir diskutieren es mit Ihnen und halten einen Impulsvortrag zum Thema Performance bei Ihnen vor Ort. Sie übernehmen nur die Reisekosten – Schreiben uns an info@retit.de!
[1] http://lt2015.eecs.yorku.ca/talks/LTWorkshop.pdf
[2] http://devopsdigest.com/application-performance-management-development-devops-1
[3] http://www.infoq.com/articles/java-profiling-with-open-source
[4] http://www.informatik.uni-jena.de/dbis/veranstaltungen/2011/20110112_Lasttests_von_Webanwendungen.pdf
[5] http://www.performance-symposium.org/fileadmin/user_upload/palladio-conference/2014/slides/20_wessbas.pdf



